论文提出了一种新的RNN结构–切片循环神经网络(SRNN),提高了训练速度的同时还提高了情感分类效果。所谓的切片指的是将输入序列分割成若干最小序列,每个短序列分别用RNN处理,然后按照切片的逆过程,再把各个短序列的表示作为输入再次用RNN处理,直到表示出整个句子。
论文地址:https://arxiv.org/ftp/arxiv/papers/1807/1807.02291.pdf
论文笔记:https://zhuanlan.zhihu.com/p/44526426
论文代码:作者本人的代码-keras
实验数据: Yelp2013-2015,Amazon
(1)模型创新与贡献
本文提出了一种新的模型,称之为SRNN,实际上与其说是一种新模型,倒不如说是一种新的结构化处理方式。因为论文并没有对模型的内部结构进行任何改造,实际上就是用现有的RNN模型,但是处理方法上有改进,不再是传统的把整个句子直接用一个RNN进行处理的方法,而是把长句子划分成短句子,然后先用RNN对短句子建模,再把短句子的表示作为输入,再次使用RNN来进行长句子的表示,逐渐递归,直到表示出原始的整个句子。
该方法的优点是加快了训练速度,实际上相当于把对一个长句子的处理变成了对多个短句子的处理,并且很多短句子的处理是可以同时进行的,因为对每个短句子使用的是不同的RNN,彼此之间独立运算。因此实际上这种方法增强了RNN的可并行性。
(2)模型详解
具体来说,切片指的是将输入序列分割成若干最小序列(最小序列长度由n和k决定,其中n表示每次分割的子序列个数,k表示分割的次数)。假设句子长度为8,以n=2,k=2为例,那么我们将对句子切分两次,每次把所有序列切分成2份。第一次切分的时候,长度为8的句子将被切分为两个长度为4的序列;第二次切分的时候,每个长度为4的序列将被切分为两份,所有将会得到4个长度为2的序列。
RNN处理句子的过程实际上就类似于上述切片过程的逆过程,切片是逐渐分割句子,而处理句子的时候则是逐渐合并序列的表示。由于我们切分了2次,所以切分过程中实际出现过3种不同长度的序列(2,4,8),对应于这三中不同的序列,SRNN有三层RNN,分别标号为0,1,2,那么对于第i层RNN,序列的个数为$n^{k-i}$,序列的长度为$\frac{T}{n^{k-i}}$,其中$T$为原始句子的长度(本例中$T$=8)。第i层有$n^{k-i}$个序列,那么也就需要$n^{k-i}$个RNN分别对每个序列进行表示。本例中,第0层有四个序列,那么需要4个RNN,然后我们分别取这4个RNN的最后一个时刻的输出作为当前这个长度为2小序列的表示,分别记作$h_2^0,h_4^0,h_6^0,h_8^0$(因为分别是第2,4,6,8个单词对应的输出),接下来,我们再以把这4个第0层的输出作为第1层的输入,第1层对应着2个长度为4的序列,所以需要2个RNN,第一个RNN以$h_2^0,h_4^0$为输入,第二个RNN以$h_6^0,h_8^0$为输入,那么就又会得到两个隐层输出$h_4^1,h_8^1$,然后再以这两个隐层输出作为第2层的输入,第2层RNN对应着1个长度为8的序列,因此只需要1个RNN,输入为$h_4^1,h_8^1$,输出最终整个序列的表示$h_8^2$【即下图中的F】。具体直观过程看下图就很容易理解了:
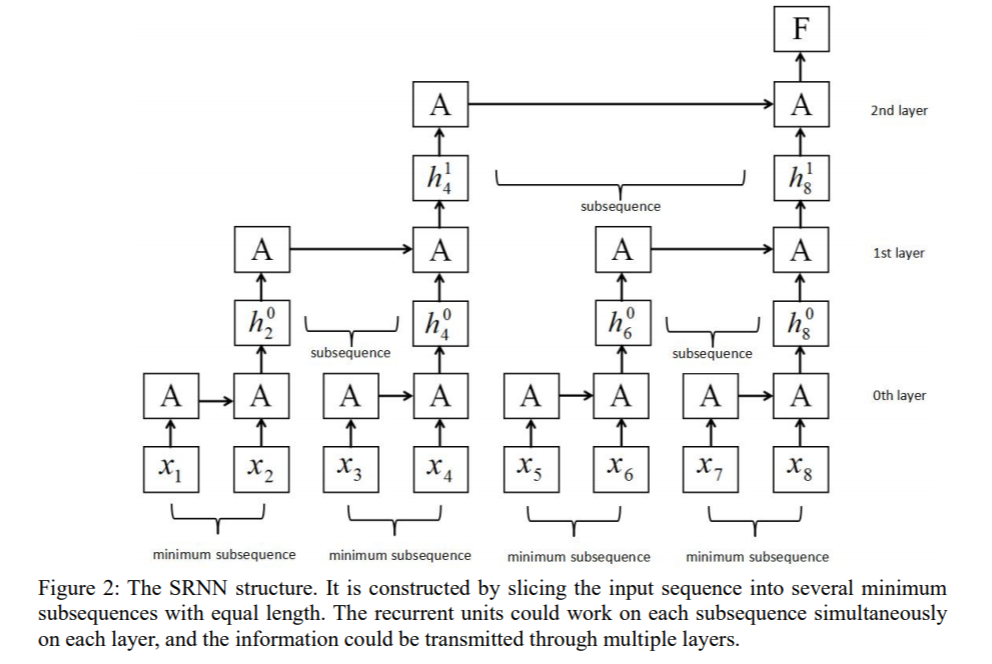
如上图所示,总共使用了$n^0+n^1+\cdots+n^k$【本例中为1+2+4=7】个RNN,RNN虽然多了,但是每个RNN的参数少了,基本上每个RNN的输入都是n个时刻【第0层除外】,并且每一层的多个RNN之间的运算是可以并行的,因此可以减少训练时间,加快训练速度。
另外,作者还给出了证明,RNN相当于是SRNN的一个特例,这个证明虽然有些繁琐,但是并不难理解,文中也写得很清楚,就不在这里说了,有兴趣自己看啊。知乎的笔记也详细讲解了。
(3)实验和结果
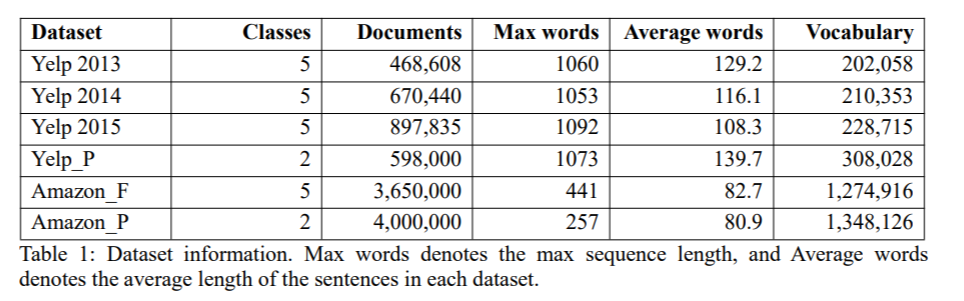
实验采用的数据是yelp数据和Amazon数据,详细情况如下:
实验结果如下: