这次调研的主要是CMU的研究团队关于MOOC的数据挖掘行为分析的一些论文,有二十余篇。
在线教育调研3——CMU相关论文
(1)Sentiment Analysis in MOOC Discussion Forums:What does it tell us?
论文地址:https://www.cs.cmu.edu/~mwen/papers/edm2014-camera-ready.pdf
论文介绍:本文着重研究mooc论坛中的情感分析,具体内容包括以下两个个方面:
- 1、课程级别的情感分析,即分析每个课程的情感随时间的变化。
- 2、用户级别的情感分析,即分析一个用户在论坛中表达的内容中的情感和浏览论坛时看到的内容中的情感对这个用户辍学的影响。
论文目标:
- 分析论坛情感和辍学之间的关系【课程、用户两个级别的分析】
- 论坛中不同主题的讨论中蕴含的不同情感,以及不同主题表达情感的用词选择
- 主题、情感、辍学率等随时间变化的趋势
实验数据: 实验数据是三门mooc课程的数据:
- 1、Accountable Talk: Conversation that works:一门谈话艺术教学课程,简称Teaching课程
- 2、Fantasy and Science Fiction: the human mind, our modern world:一门文学课程,简称Fantasy,讲解科幻小说相关的东西
- 3、 Learn to Program: The Fundamentals:一门Python编程课程 我们有以上三门课程的所有论坛评论,以及评论的用户信息、发布时间。 对于第一门课程,还有所有学生的最后一次登录时间信息。
研究方法: 1、对于课程级别的情感分析,作者将论坛内容分为为不同话题,使用 Brown clustering的方法对论坛内容进行自动聚类,每个聚类作为一个话题,然后人工为每个话题从该话题聚类结果中选取关键词,总共选择了四个话题:课程整体(Course),授课(Lecture),作业(Assignment),同学互评(Peer-assessment)。每个主题的关键字这里不再赘述。 然后用这些关键字作为话题标志,如果一个论坛回复中包含该话题中的一个或多个关键词,那么该回复就认为是有该话题有关的。 接下来,为了衡量情感,作者使用正负情感词比例来衡量情感,即第$t$天内发表的所有论坛回复中,积极情感词数/消极情感词数即为第$t$天的情感系数,记作$x_t$,但是一天之内的回复数量不够,会使得情感波动过大,为了平滑,采用7天情感系数的平均值作为指标,即:
\[MA_t=\frac{1}{k}(x_{t-k+1}+x_{t-k+2}+\cdots +x_t)\]然后作者绘制了整体课程的情感系数与辍学人数随时间变化的图标,探究两者之间的关系。作者使用课程整体(Course)话题的论坛回复中的情感作为学生对这门课的整体情感。
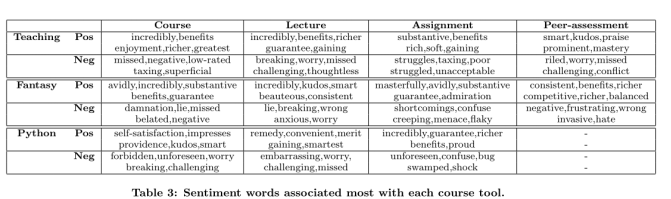
另外,作者还统计了每门课与每个主题最相关的关键情感词,采用PMI对情感词排序,以此找出与当前话题最相关的情感词: \(PMI_{w, {TopicKeyword}}=\frac{P(w, { TopicKeyword })}{P(w) P({TopicKeyword})}\)
$P(w)$表示情感词$w$在评论中出现的概率,$P(TopicKeyword)$表示当前话题的话题词在回复中出现的概率,一条回复出现一个关键词和多个关键词不做区分,都认为与当前话题有关。$P(w,{TopicKeyword })$表示情感词和话题词共同出现在同一回复中的概率。通过这种方法,作者找出了每个话题最相关的情感词:
2、对于用户级别的情感分析,作者主要分析了两方面的内容,第一种是一周内用户发布的评论中的情感,第二种是用户一周内回复过的论坛话题中所蕴含的情感。对于积极和消极情感分别计算评分,比如:用户一周发布回复的积极情感词数/用户一周发布回复的所有单词数,即为用户个人发布的积极情感系数,记作Individual Positivity。消极的则记作Individual Negativity,论坛话题影响相应的记作Thread Positivity和Thread Negativity。
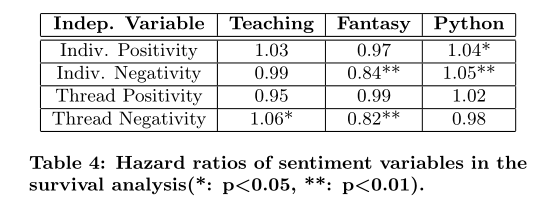
作者使用生存模型,预测上述四个因素对下一个星期学生辍学的影响大小。
实验结果:
实验1的实验结果:
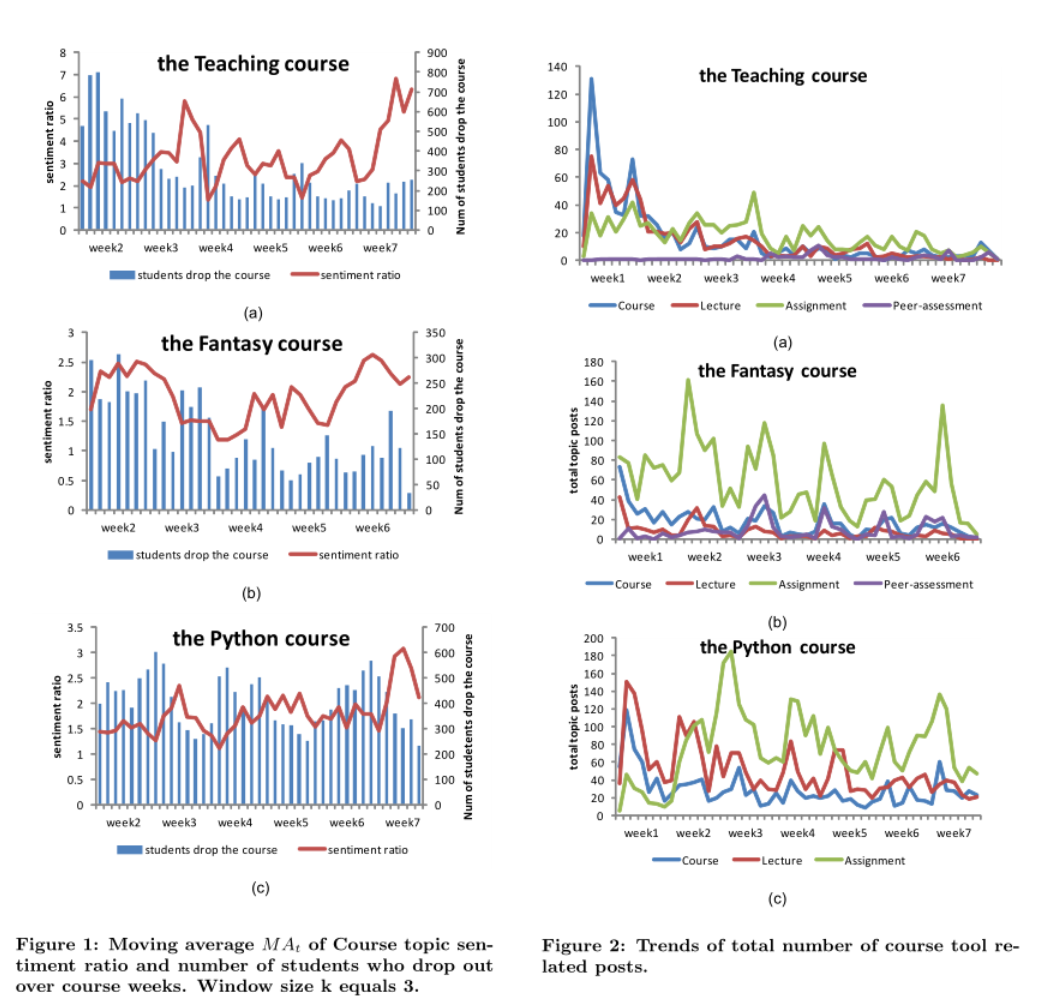 可以看到一门课整体的情感系数和辍学的人数有关系。图2是每门课每种话题回复的数量随时间的变化,可以由此看到学生在不同时间段对不同话题的讨论度是不同的。
可以看到一门课整体的情感系数和辍学的人数有关系。图2是每门课每种话题回复的数量随时间的变化,可以由此看到学生在不同时间段对不同话题的讨论度是不同的。
实验2的实验结果和想象的并不相同,并非积极情感就一定会降低辍学率,消极情感就一定会提高辍学率,需要针对具体课程具体分析,如Fantasy课程中经常出现的一些消极情感词是在讨论科幻小说的内容【僵尸、灾难等】,这体现处理对课程的参与,反而会降低辍学率。所有盲目的对所有课程进行情感分析不可取,因为噪声很多,但是针对一门课程的情感分析是有意义的。
改用mooc相关的情感词典可以提高准确率。
(2)Exploring the Effect of Student Confusion in Massive Open Online Courses
论文地址:https://www.cs.cmu.edu/~diyiy/docs/ls15.pdf
论文介绍:主题是mooc论坛中困惑的影响。作者在论文中量化困惑的影响,使用论坛行为和点击流数据设计了一个分类模型来自动识别表达困惑的帖子。使用生存分析量化困惑对学生辍学的影响。 结果表明用户表达和接受到的困惑越多,留下来的可能性越低【辍学的可能性越高】,这些学生接收到指导的话可以帮助减小这种影响。作者探索了困惑在不同上下文中对课程的不同方面的不同影响,总结了设计干预指导措施有主意提高mooc学生的保留率。
探究不同程度的困惑对学生流失的影响。两个贡献: 从理论上讲,通过探究困惑对学生生存的影响,作者发现了学生的困惑与他们退出MOOC课程之间的几个重要联系。在实践上,我们的研究结果为开发潜在的干预措施提供了指导,这些干预措施可能通过为困惑的学生提供及时的帮助和支持来促进学生留下来。
研究方法: 我们创建了一个人工标注的语料库,用于开发自动测量学生困惑的方法。其次,我们将每个帖子表示为一组特性,作为机器学习模型的输入。最后,我们建立了一个基于手工编码数据的统计模型,并对其性能进行了评估。
1、分类器衡量困惑程度。设计了一个分类器可以预测学生的困惑程度,这个分类器考虑学生的语言选择和视频观看模式。为了给学生提供识别困惑的机会,我们建立了机器学习模型来自动识别学生在课程论坛上发表的帖子中表达的困惑程度。这些模型使用统计过程将一组输入特性映射到一组输出类别。在我们的工作中,我们从学生的点击行为和他们的发布行为中提取输入特征,包括课程中的点击模式、领域特定内容词的出现以及高级语言特征。输出是一个数值,表示每个帖子中表示的困惑程度。
使用逻辑回归模型和10次交叉验证的方法评估性能【Acc】。
预测困惑的模型使用的输入特征有3个,分别为:
- 1、点击流模式:比如重看教学视频可能表示困惑。四个动作组成的序列:quiz,lecture,forum,course materials。最大序列长度为4,选取最多的20中序列作为特征模式。
- 2、语言特征:LIWC词典。人称代词、情感词、口语。
- 3、问题特征:这是不是一个问句,问好数量、疑问词开头、常见疑问句式。
结果:Acc:80.3【代数】,60.6%【微观经济学】,发现技术性课程比非技术性课程困惑程度高,还对比了不同群体【性别、年龄、受教育程度】的用户困惑程度不同。
2、生存分析 使用生存分析预测困惑程度对辍学的影响,与上一篇类似,根据用户这一周的困惑程度预测用户下一周的辍学倾向性,从而确实用户困惑程度与辍学之间的关系。具体如下:
- 因变量:辍学与否。
- 自变量
- 一周内的帖子总数
- 发起一个线程【话题】
- 独立变量
- 表达困惑
- 该学生发起的线程中接受到的困惑
- 该学生参与的其他线程中接受到的困惑
- 困惑被解决的线程数
- 被回复的线程数
实验数据:
本文的数据集包括两门Coursera课程:一门数学——代数课和一门微观经济学课。代数课拥有2126个活跃用户(活跃用户指在课程论坛中至少发布一次帖子的用户)和7994个论坛帖子;微观经济学拥有2155名活跃用户和4440个论坛帖子。每个线程提供了一个标志,指示是否解决了问题。两门课程各为期12周。
除了论坛记录,每个学生与课程材料的互动(学生点击)也记录在点击流中。代数的学生点击量为8,686,230次,微观经济学的点击量为2,709,053次。这个点击流数据为我们提供了一个机会来研究点击模式和学生困惑之间的关系。大约3.4%的代数学生和8.3%的微观经济学学生至少在论坛上发过一次帖子。
另外,为了训练困惑程度预测模型,作者使用MTurk人工标注平台标注数据,每个帖子标注1-4,代表困惑程度评分。
实验结果: 接触困惑确实会增加辍学率,但是回复和解决问题有助于缓解这一影响。 用户的点击流模式可以在一定程度上解释用户对哪方面有困惑,可以辅助预测用户发布的线程问题是关于哪一方面的困惑。据此分析学生对不同方面的困惑的不同。 我们的研究结果表明:
- (1)学生在MOOC论坛上表达的困惑越多,接触到的困惑越多,学生在学习社区中保持活跃的可能性就越小;
- (2)帮助解决或提供对学生困惑的反应,减少他们在课程中的退学;
- (3)不同类型的干扰对辍学的影响程度由具体课程决定。在我们的数据中,在技术课程中,测验的混淆导致了最高的辍学率,而在技术含量较低的课程中,对课程的困惑通常会导致辍学率更高。
(3)Linguistic Reflections of Student Engagement in Massive Open Online Courses
论文地址:http://www.cs.cmu.edu/~mwen/papers/icwsm2014-camera-ready.pdf
论文介绍:自动分析论坛语言,挖掘学生参与这门课的动机与投入,而学生参与课程的目标与决心与他们的参与度以及辍学息息相关。
作为方法论上的贡献,本文研究了使用计算语言模型从论坛帖子的文本中测量学习者动机和认知投入。从两个角度量化学生参与度:
- 1、学生表现出来的继续学习下去的动力
- 2、学生对课程材料认知理解的程度(讨论参与度)
我们使用生存模型来验证我们的技术,该模型评估了这些变量对于预测随时间推移的学生损耗率的有效性。
这种方法可以有效区分学生,识别危险迹象,找到苦苦挣扎的学生,从而减少辍学率。
研究方法:
1、预测学生动机:人工标注数据,标注参与度1-7 使用五种语言特征:
- 应用词:“apply”, “try”, “utilize”, “employ”, “practice”, “use”, “help”, “exploit” and “implement”
- 需要词: “hope”, “want”, “need”, “will”, “would”,“like”, “plan”, “aim” and “goal”
- LIWC-cognitive词,比如 “thinking”, “realized”, “understand”,“insight” and “comprehend”
- 第一人称词
- 积极情感词 2、认知投入水平 衡量语言抽象程度:使用一个抽象程度词典,对句子中的词抽象程度取平均值,作为整个句子的抽象程度。
3、生存实验: 因变量:和之前一样,又是辍学与否。 控制变量:
- Cohort:二元变量,是否在第一周发表过帖子。
- 一周发布帖子的数量
- 一周在论坛中的评论数
- 一周发布帖子的平均动机,使用实验1中的模型预测动机
- 一周发布帖子的平均抽象程度
实验数据: 三门Coursera课程数据,和第一篇情感分析的那个用的数据一样:
- 1、Accountable Talk: Conversation that works:社交谈话教学课程,1146个活跃用户,5107个帖子
- 2、Fantasy and Science Fiction: the human mind, our modern world:文学课程,771个活跃用户,6520个帖子 -3、Learn to Program: The Fundamentals:编程课程,3590个活跃用户和24963个帖子。
实验结果: 参与度越高,辍学率越低;个人解释越多,抽象程度越高,辍学率越低。
(4)Towards triggering higher-order thinking behaviors in MOOCs
论文地址:https://dl.acm.org/citation.cfm?id=2883964
论文介绍: 题目是激发mooc中更高层次的思考行为。目的是研究什么样的讨论更有助于学习,探索高阶的思考行为比仅仅集中与课程材料的讨论更加有助于学习。与上一篇中的语言抽象程度有点像。为了研究这种效果是由于相关行为的参与,还是学生个人的执着的性格。作者使用两种方法:
- 1、使用倾向性得分配对在其他课程活动中表现出相似参与度的学生
- 2、探索个体在几个星期内参与高阶思考行为的差异 两项分析的结果都支持将这种效应归因于行为解释???
作者还研究了什么样的学习材料更容易引发高阶思考讨论:使用LDA对课程材料的进一步分析表明,更多的社会导向的话题比更多的生物心理学导向的话题引发了更丰富的讨论。
研究方法: 构建了一个编码手册【一系列规则】,标注每个帖子是不是高阶思考行为。 1、把学生分成三个群体:高阶思考、专注课件、不讨论。使用回归模型,因变量是测后成绩,控制变量包括测前成绩、帖子数、是否注册、是否点击视频、是否点击测验、课程网站点击数、论坛点击数。 研究高阶思维组比专注课件组的成绩更好,收获更多。
我们利用前面介绍的所有控制变量作为学生参与课程的特征,建立了逻辑回归模型,预测学生在课程中出现高阶思维行为的概率。
实验数据: cmu的课程《Introduction to Psychology as a Science》,该数据集共包含27750名注册用户的数据,以及7990篇文章和评论。其中,有1079名学习者同时进行了前测和后测,其中491人参加了论坛,共发表帖子和评论3864条。
除了论坛记录,点击流数据中还记录了与课程材料相关的学生点击量。课程记录包含1487665次学生点击。这些数据为我们提供了一个机会,监控学生与课程材料的互动过程。 流程:逻辑回归训练模型,预测学生在课程中出现高阶思维行为的概率。实验组和对照组的人进行相似行为匹配,然后预测测后成绩。高阶思维成绩更高。
实验结果: 在第一个研究问题的驱动下,我们发现,表现出更高阶思维行为的学生,通过对讨论行为所展示的课程材料进行更深入的参与,学习得更多。在这门课中,表现出高阶思维行为的学生比单纯关注课程材料的学生学得更多。这些学生也比那些经常在论坛上离题的学生学得更多。将LDA主题建模应用于课程材料的后续分析告诉我们,与生物心理学主题相比,面向社会的主题引发了更丰富的讨论,更高阶的思维行为往往在论坛的线程中一起出现。
(5)Towards Identifying the Resolvability of Threads in MOOCs
论文地址:https://www.aclweb.org/anthology/W14-4104
论文介绍: 分析mooc中问题线程被解决与哪些因素有关。mooc的问题论坛与其他百度知道等问答网站的不同之处在于:
- 1、没有最佳回答这一选项,只能标识问题已解决或者未解决。
- 2、没有奖励机制,回答者不能获得奖励
- 3、mooc允许低水平的提问,更注重大家对问题的讨论互动过程,而非单纯性的回答问题而已。
作者把一个线程中的参与者分成了以下几种用户角色:
- 1、发起者(Starter):线程问题的发起者,提问者
- 2、导师(Instructors):老师和助教同城导师
- 3、参与者(Participants):所有参与讨论的人,回复和评论都算。
线程问题是否被解决由发起者负责标记。作者研究的就是给定一个问题和一系列的回复,影响该问题是否会(被标记为)已解决的因素。
研究方法:
作者把一个线程中的参与者分成了以下几种用户角色:
- 1、发起者(Starter):线程问题的发起者,提问者
- 2、导师(Instructors):老师和助教同城导师
- 3、参与者(Participants):所有参与讨论的人,回复和评论都算。
作者尝试分析了几个可能对mooc问题可解决性有影响的因素:
- 1、启动影响:问题的发起者吸引其他人来参与回答讨论的倾向性。使用线程发起者的影响程度衡量这个指标,包括四个方面:
- 问题爱好者:根据用户发起的线程数对用户分级
- 用户参与度:根据用户参与讨论的线程数对用户分级
- 解决优先级:根据由当前用户发起的线程并且已解决的数量对用户分级
- 回复被表扬度:该用户的回复中获赞的比例
- 2、专家参与:回答者贡献有用回答的倾向性。专家的定义有两类群体:
- (1)导师:包括所有的老师和助教
- (2)声誉排名前1%的学生,衡量学生$u$声誉的方式如下:
\(\begin{aligned} \operatorname{score}(u)=& \alpha u_{Pst}+\beta u_{Rep}+\gamma u_{Res}+(1-\alpha-\beta-\gamma) u_{Uvt} \end{aligned}\) 其中$u_{Pst}、u_{Rep}、u_{Res}、u_{Uvt}$分别对应于前面提到的问题爱好者、用户参与度、解决优先级和回复被表扬程度。
- 3、线程流行度:线程的受欢迎程度、流行度与线程是否可以被解决有关,以总共获赞数和最高获赞数来作为衡量指标。
- 4、友好程度。回答者的回答的友好程度对新手能否继续学习下去很重要,讥讽的态度更容易打击初学者。使用礼貌词匹配的方法衡量:
- 以感谢开头:发布问题时是否用了感谢
- 以感谢结尾:收到别人的回复时是否表示了感谢
- 感谢数量:衡量该线程总体的友好程度,计算整个线程感谢相关的个数
- 表示尊重的礼貌用语词数:比如Nice、Great或Awesome等词
- 友好问话词数:捕捉友好问话词的使用个数,比如please、will等
- 5、内容匹配度。用来表述回答是否是针对用户发起的问题,描述回答与问题的相关性。使用Eigenword bipartite graph描述语义相似度。二部图中的每个节点都是给定单词对应的特征字3,左边表示线程启动器中出现的单词,右边表示给定回复中的单词。使用余弦相似度度量计算问题和回复的相似度评分,使用余弦相似度排名前三的相似值和TF-IDF相似度以及最大问题长度辅助计算匹配度得分。
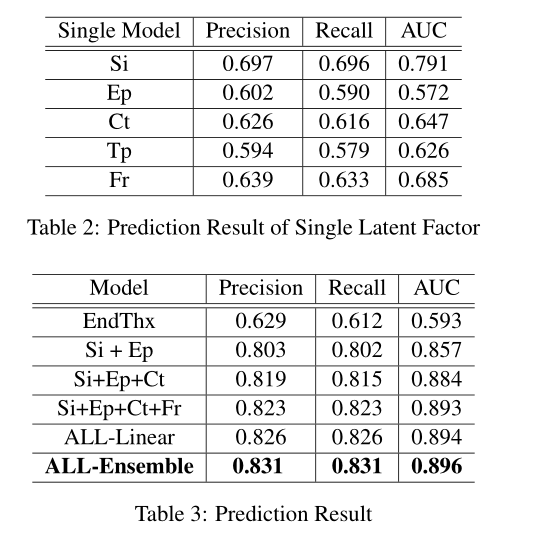
作者使用结构方程模型Structural Equation Model (SEM)来验证每个潜在因素对线程可解决性的影响。使用预测模型评估识别问题可解决性研究的通用性。
之后作者使用全体逻辑回归模型,预测一个线程的可解决性。对五个影响因素分别构建5个逻辑回归模型,然后再使用下面的公式集成这些子模型的输出结果,相当于是结合了5个不同方面预测可解析性。
\[\ddot{R}_{j}=\frac{1}{1+e^{-\sum_{i=1}^{k} \alpha_{i} \cdot \dot{R}_{ij}}}\]实验数据: Python编程课程论坛,将论坛集限制为集中于讨论课程内容的子论坛【有一个已解决按钮】,在最终的数据集中,共有2508个线程(1244个已解析线程),2896个用户(12名教师和工作人员)至少有一个帖子。每个问题都与一个标签相关联,该标签指示是否解决了问题
实验结果: 影响系数:启动影响(0.62)、专家参与(0.59)、内容匹配度(0.18)、友好程度(0.08)、线程欢迎度(0.05)。
预测实验结果:
(6)“Turn on, Tune in, Drop out”: Anticipating student dropouts in Massive Open Online Courses
论文地址:https://pdfs.semanticscholar.org/c134/1b4b24363dc09ba1659c448dcce8442697e6.pdf
论文介绍:
首先,我们使用一个被称为生存模型的统计模型来评估中途辍学的增加和减少的因素,而不是仅仅关注课程的完成。其次,我们在分析指标中加入了来自社会网络分析的社会亲缘关系。
论文数据:
来自Coursera的文学课程,虽然作者没有说名字,但是我想应该还是那个关于科幻小说的课程Fantasy and Science Fiction: the human mind, our modern world吧。
在课程的第7周,当我们收集数据时,有771名用户至少发布过一次帖子,我们从论坛的互动中构建的社交网络图共包含3848条边。所有在第一周内开始工作的学生都被标记为第1组,而所有在第二周开始工作的学生都被标记为第2组。
研究方法:
作者首先定义了衡量发帖行为和社会网络行为的标准
- 1、发贴行为
- 线程发起者,二元标志,标识一个学生某一周是否发起过一个线程。子线程发起者,二元标志,指的是一个学生某一周是否发起过子线程。子线程指的是他在线程内的某个发帖多于三个人回复,则认为他的这个帖子实际上是发起了一个讨论,称为子线程。
- 帖子长度-指的是一个特定用户的发帖数量。帖子密度,指的是帖子长度除以学生的生存时间,生存时间指的是第一个发帖时间和最后一个发帖时间的差值。
- 内容长度,指的是用户在论坛中发言的字数。内容密度-指的是内容长度除以学生生存时间。
研究上述论坛特性的动机是为了深入了解: - 1)与只回复线程/子线程的人相比,线程启动者和子线程启动者存活的概率是否不同; - 2)发帖方式是否对学生的生存有影响; - 3)学生的生存是否受到启动线程/不启动线程/子线程以及随后参与/不参与积极讨论的影响。例如,当一名学生突然发布了一连串帖子时,这是否是他们对这门课程感兴趣的一个潜在指标,以及他们后来退学的可能性是变大了还是减小了。
- 2、社会网络行为
- 度中心性-使用平均度来衡量;特征向量中心性-基于节点的连接来度量网络中节点的重要性;中间性-节点出现在网络中节点之间最短路径上的频率;接近中心性-度量给定起始节点到网络中所有其他节点的平均距离;通过与Borgatti等人的[14]相似的类比,我们可以说,特征向量中心性可以捕捉到学生互动模式的长期直接和间接效果,以及它们在MOOC网络中连接的含义,而度中心性可以捕捉到更直接的效果。
- 平均集群系数-表示节点如何嵌入到它们的邻域中,这可以看作是网络中小世界效应或聚类的一个总体指标。将这一因素作为辍学的潜在指标进行研究的动机是,如果在讨论论坛中没有小圈子,学生就不会找到足够活跃的伙伴来参与讨论。邻里关系更加紧密会影响学生在网络中的结构位置,进而促进讨论,促使学生留在课堂上。
-
偏心率(离心率)。表示给定的起始节点到网络中最远节点的距离。在MOOC网络中,研究这一变量的重要性在于直观地监控响应时间如何影响学生的参与,这是衡量中心度的一个极端指标。在MOOC中,相对于处于网络边缘的高电商中心的学生,偏心率低的学生更容易处于图的中心,因此更容易接受信息。而且,如果学生部分地脱离了网络中核心或核心学生群体的影响,他们辍学的机会可能会增加。
- 权威和中心分数。这衡量存储在一个节点的信息有多少价值,并且这个节点连接的质量。在MOOC课程中,权威分数高的学生是那些让其他学生参与讨论的学生。中心得分高的学生是那些参与由许多主动学习者发起的讨论的学生,如线程启动者或子线程启动者。在我们的数据中,我们发现这两个指标之间有很强的相关性。
- 3、控制变量
虽然我们的目标是调查每周参与模式的影响,但我们必须认识到,学生在整个参与过程中都具有稳定的特点。在我们的工作中,我们只纳入了一个控制变量,即学生属于哪个队列。在MOOC中,学习者可以随时加入课程,直到课程积极运行为止。队列号表示学生开始参加课程的星期。
- 4、生存模型
生存模型可以看作是一种回归模型,它捕捉了生存概率随时间的变化。生存模型是一种比例概率逻辑回归的形式,在此模型中,基于一些存在的预测因子,在每个时间点对故障发生的可能性进行预测。每个预测因子上的估计权重称为危险比。预测器的危险比指示了故障发生的相对可能性如何随着相关预测器的增减而增减。
实验结果:
作者的初步研究揭示了不同时期开始的研究对象在整个研究过程中的不同轨迹。最早开始的学生完成的课程更多,退学的可能性更小。后来的学生通常表现出更积极的参与对于他们加入之前一周的课程的课件,而不是从第一周的课件开始,作者猜测他们可能是为了赶上这个课程。
课程的少数核心参与者主要来自最早开始课程的那一组学生。
最早加入的学生更有可能积极参加讨论课程的早期部分,后来加入的学生和他们进行讨论的可能性不高。后来的学生更有可能留在外围,早来的学生则继续相互交流。后来的学生发帖率低于先来的学生。这种模式要么指出了早入校的学生和晚入校的学生之间动机上的差异,要么指出了晚入校的学生在正确融入课程方面面临的挑战。
(7)Shared Task on Prediction of Dropout Over Time in Massively Open Online Courses
论文地址:https://www.aclweb.org/anthology/W14-4107
论文介绍: 预测任务是预测mooc随着时间推移的消耗。根据学生一周MOOC活动的行为数据,预测学生在一周后是否会停止积极参与。
论文数据:
包括分析Coursera提供的6家mooc课程的数据。来自一个MOOC的约3万名学生的数据作为培训数据分发,包括论坛数据(SQL格式)和点击流数据(JSON格式)。
研究方法:
实验结果:
(8)Towards an Integration of Text and Graph Clustering Methods as a Lens for Studying Social Interaction in MOOCs
论文地址:https://files.eric.ed.gov/fulltext/EJ1045994.pdf
论文介绍: 本文特别关注整合这一领域中已有的两种技术,一种与社交网络结构相关。
我们使用该模型在三个mooc的每个线程讨论中识别出20个新兴的子社区。有2-4个子社区的平均辍学率与总体辍学率有明显差异。
当学生从一个子论坛转到另一个子论坛时,他们在与不同兴趣、目标和关注点相关的讨论中与不同的学生子集交互时,可能会采取不同的立场。从论坛的结构来看,可以构建一个基于线程内回复-评论结构的社交网络图。这种网络结构为学生在MOOC中的社会参与提供了一种视角,它可能反映了学生的价值观和目标。在这些讨论中,学生们所讲的课文提供了一种补充的观点。
论文数据: 还是那三个课程。
研究方法:
创建了一个LDAMMSB模型,可以提炼出20个子论坛,每个子论坛有一个话题,每个学生可以属于多个子论坛。使用生存模型分析,因变量是辍学率,独立变量是20个话题。
实验结果:
每个课程的20个话题中都有几个的辍学率明显高于或低于整体的平均辍学率,然后分析发现辍学率偏低的子论坛讨论的话题与课程内容更加相关,而辍学率偏高的子话题讨论的内容与课程更加无关。
(9)Transfer Learning for Predictive Models in Massive Open Online Courses
论文地址:Transfer Learning for Predictive Models in Massive Open Online Courses
论文介绍: 题目是在mooc中预测模型的迁移学习。基于用户过去的课程信息预测他是否会中途辍学。并且评估了多种迁移学习方法。基本思路是使用某个课程之前的开课信息训练模型,并在当前开课学期微调模型,从而使得模型可以更好地实时预测辍学率。【很多可能一般不是第一次开课,而是每学期都会开课,利用一门课程之前已经结束的学期的课程数据,来预测当前正在开课的学期的辍学率】
但是有几个问题需要考虑:
- 课程内容可能略有不同:由于mooc还在不断发展之中,课程的许多方面都在发展。因此学习者每次学习处于不同的环境中,可能会使他们有不同的互动和行为。
- 课程的老师和学生们不同:后续课程中有不同的学生群体、助教群体,在某些情况下,还可能有不同的讲师。
- 有些变量可能不会迁移:有些变量可能不会出现在后续的发展中。比如在某个特定课件上花费的时间,后续的开课学期中可能这个课件不会再出现了。
论文数据: 一门课程,MIT开设的Circuits and Electronics课程的三次开课信息。我们分别把三次开课学期命名为A、B、C,三个学期的报名人数/取得合格证书的人数分别为154753/7157, 51394/2987和29050/1099。
尽管每个学期的课程内容、课程人数等都不同,但是在学生的交互中聚集的数据允许我们提取一个公共的纵向变量集合。如下表所示:
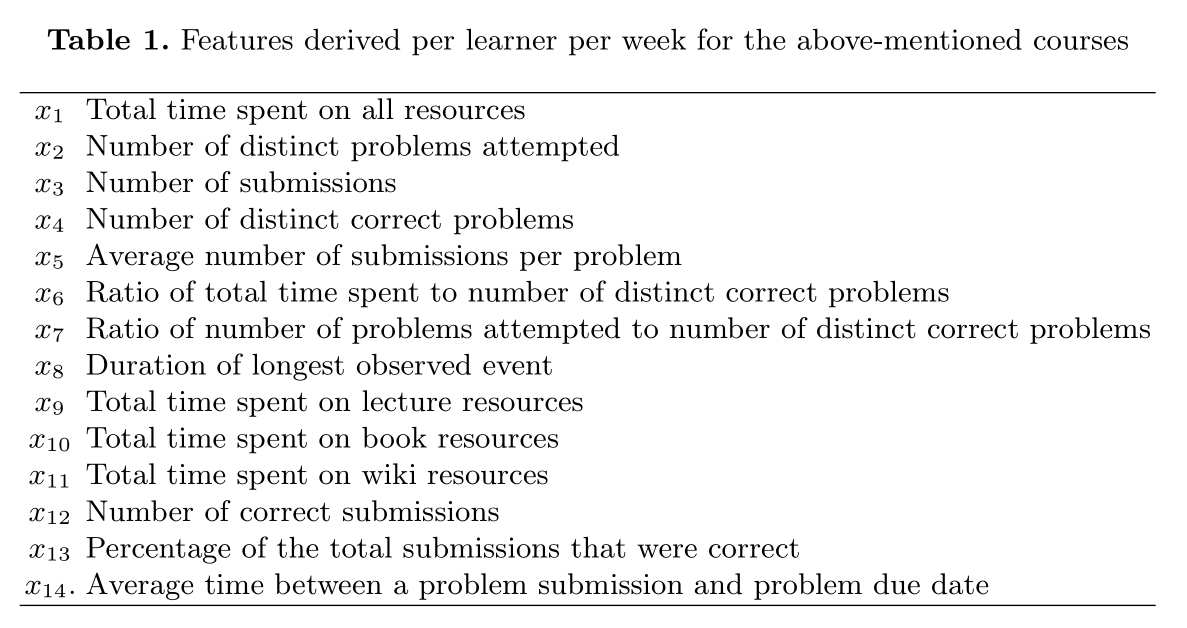
研究方法:
具体地,我们对于一个学生到第i周的学习数据,预测该学生第i+j周到k周是否依然会留下来,j属于{1,2,……,k-i}。k表示该课程一共有多少周,j表示领先度,所谓领先度是因为作者不仅仅是预测下一周的辍学情况,而是可以预测当前周之后第j周的辍学情况,这个j就称作领先度。如果该学生在一周内至少提出过一个问题,我们就认为他留下来了没有辍学。
利用历史信息的两种方法:
- 1、整个历史,预测第i周之后的辍学,则使用第一周到第i周的所有历史
- 2、固定历史窗口大小wz:使用是一个固定的窗口大小,仅仅使用第i周之前的wz周的历史信息预测第i周之后的辍学。 另外,作者还提出了两种预测问题(学习方式):
- 1、现场学习:在有限的预测场景中,使用一个正在进行的课程中收集到的信息来预测。
- 2、迁移学习:使用之前的开课信息和迁移学习的方法来进行预测。(本文主要内容) 性能指标:由于数据不均衡问题(辍学率90%),作者使用AUC值而不是Accuracy作为衡量指标。
对于迁移学习,作者又分成了两种:
- 1、归纳迁移:目标学期有少量标注数据可以获得使用
- 2、直推迁移:目标学期没有标注数据可以获得使用
在接下来的表示中,我们使用S表示源学期,T表示要预测的目标学期。
几种迁移方法:
- 1、一种天真的迁移方法(朴素迁移法):在S上训练具有优化岭回归参数的逻辑回归模型,然后将其应用于T。
- 2、归纳迁移学习方法
- 多任务学习法:$\left{\begin{array}{l}{w_{S}=v_{S}+c_{0}} \ {w_{T}=v_{T}+c_{0}}\end{array}\right.$
\(\begin{array}{l}{\left(w_{S}^{*}, w_{T}^{*}\right)=\arg \min _{v_{S}, v_{T}, w_{0}} \sum_{i=1 : n_{S}} l\left(x_{S i}, y_{S i}, w_{S}\right)+}{\sum_{i=1 : n_{T}} l\left(x_{T i}, y_{T i}, w_{T}\right)+\frac{\lambda_{1}}{2}\left(\left\|v_{s}\right\|^{2}+\left\|v_{T}\right\|^{2}\right)+\lambda_{2}\left\|c_{0}\right\|^{2}}\end{array}\) 实验中,作者使用$\lambda_{1}=0.2$,$\lambda_{2}=0.8$,分别控制独立部分和共享部分的权重。
-
用先验方法进行逻辑回归:解决多任务学习方法每个协变量赋予相同权重的问题,对每个协变量赋予不同权重,并且权重可以变化,假设每个权重符合高斯分布,把数据分成十组,用着十组数据估计每个权重的高斯分布参数,作为先验分布。
- 3、直推迁移学习法:我们虽然没有T的标注数据,但是我们有T的输入数据,即用户的特征,所以我们训练模型的时候,对于S中的不同学习者给与不同权重,衡量S中的每个学习者与T中学习者的相似性,相似度越高的数据越重要。
汇总一下,作者实际上将预测问题即解决方案分成了好几种,如下图所示:
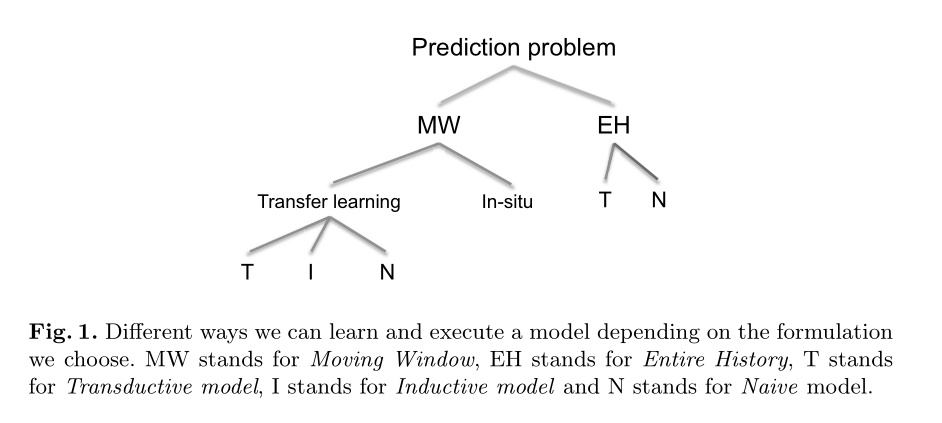
实验结果:
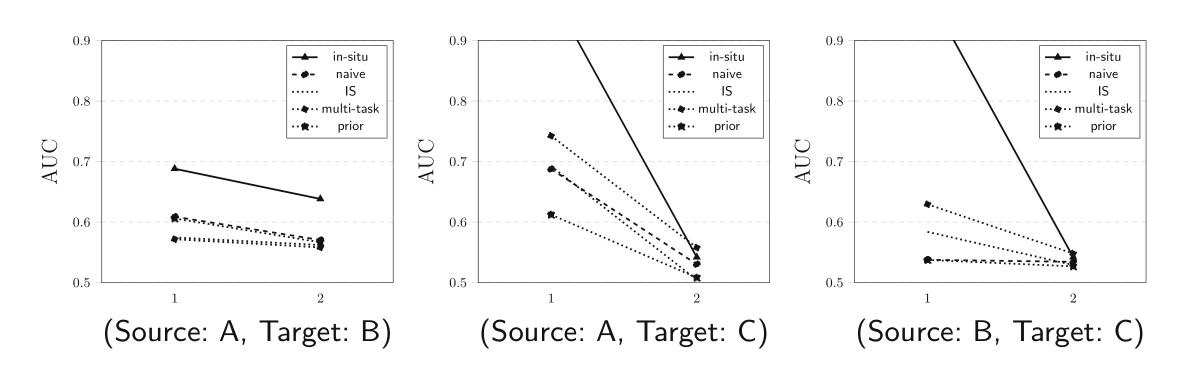
实验结果如下图所示,横坐标是领先度,纵坐标是AUC。B->C仅仅用Naive方法就很高,可能是因为B和C相比课程变化不大。

固定窗口的形式实验结果如下(窗口大小为2):
(10)Social Factors that Contribute to Attrition in MOOCs
论文地址:http://www.cs.cmu.edu/~mwen/papers/p197-rose.pdf
论文介绍: 这篇论文与第6篇基本上是一样的,除了使用的数据更小。 题目是mooc中对辍学有影响的社会因素。本文探讨了大规模开放网络课程(MOOC)中学生的辍学行为。我们使用生存模型来衡量三个社会因素的影响,这三个社会因素对参加过课程讨论论坛的学生在学习过程中出现的磨耗做出了预测。
论文数据:
来自Coursera的一门课程Accountable Talk™: Conversation that Works。60000名学生报名参加,但是只有25000个学生访问过课程材料至少1次。只有大概5%的学生发过帖子。
研究方法: 使用MMSB方法得到论坛社交网络的软划分,该方法一个学生可以分配到多个子社区。该模型可以跟踪学生在参与过程中在子社区之间移动的方式。在我们的社交网络代表中,每周的参与都被视为一个不相交的网络。实际上只识别到了3个子社区。
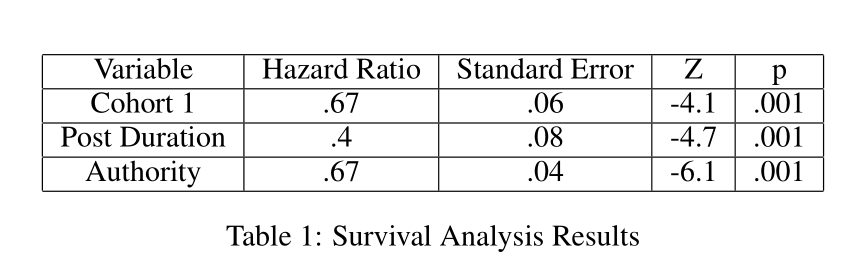
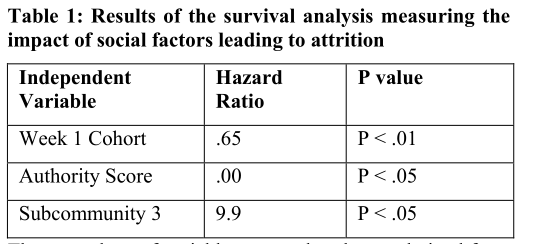
使用生存分析分析3中社交因素对辍学的影响。第一周进入与否、权威分数和子社区3这三个变量。
实验结果:
(11)Identifying Latent Study Habits by Mining Learner Behavior Patterns in Massive Open Online Courses
论文地址:http://www.cs.cmu.edu/~mwen/papers/cikm14-mwen.pdf
论文介绍: 论文题目是通过挖掘网络公开课学习者的行为模式,发现潜在的学习习惯。通过点击流分析识别这些模式,可以为在线环境下的学生信息搜索和学习提供更有效的个性化支持。我们提出了一种新的方法,通过挖掘学生在个别课程中的习惯性行为来表征mooc课程的类型。我们用局部N-gram模型将学习会话建模为活动和活动序列的分布。这种表征提供了对学生的习惯行为与课程较高或较低的成功率的关系的洞察性。我们还研究了上下文信息,如一天中的时间或用户的人数等统计信息,与学习会话的类型有关联。
论文数据: 来自Coursera的两门课程:一个关于virtual instruction(VI),另一个关于personal financial planning(FP).
研究方法: 作者使用的行为(只有斜体的活动会有成绩分数):
- 视频:看视频
- 作业:看作业、提交作业、开启一个同学互评、提交一个同学互评
- 测验:提交视频内测验、浏览每周测验、提交每周测验、浏览期末测验、提交期末测验
- 调查:浏览课前和课后调查、提交一个调查
- 参与论坛:浏览一个线程、发布一个帖子、回复他人的帖子、赞别人的帖子、踩别人的帖子
- 浏览课程材料:
从每个用户的每个回话内提取信息,包括:时间信息、使用的设备信息、回话时长、用户个人信息。
使用N-gram话题模型,采样单词和单词短语,使用概率模型构建话题。与传统的关联规则挖掘不同,我们使用分类规则挖掘在上下文日志中发现一小组规则,这些规则预测由主题建模生成的会话类型。
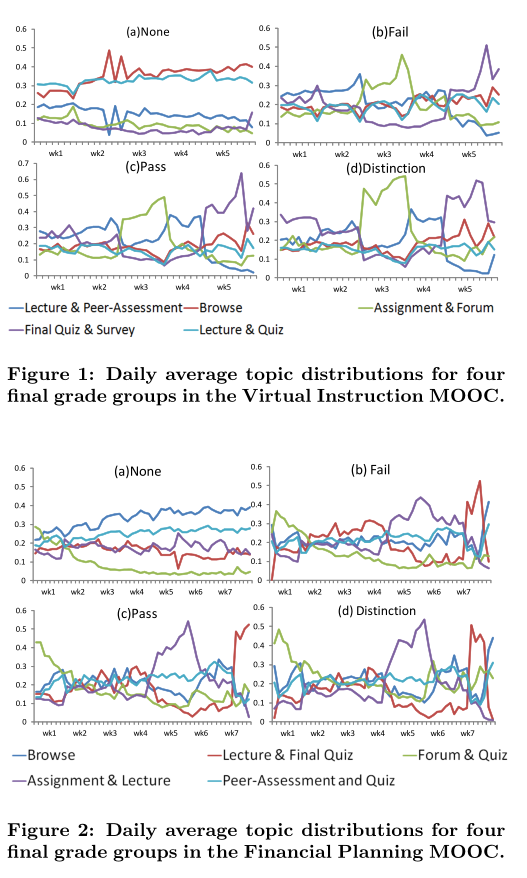
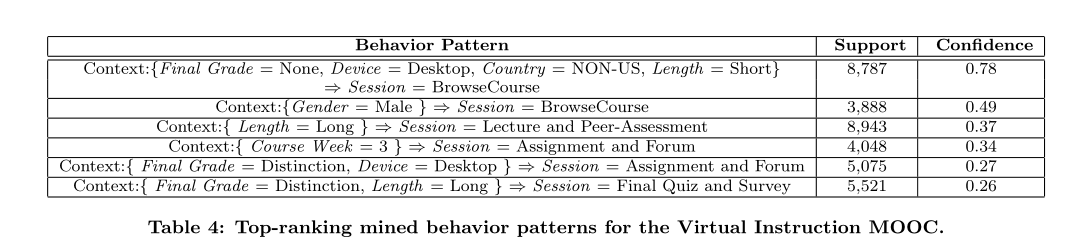
基于话题,对回话进行分类,然后对排名靠前的回话总结为行为模型,即将回话分类为不同的行为模式,一次分析不同成绩的人行为模式有何不同。
实验结果:

12、Question Recommendation with Constraints for Massive Open Online Courses
论文地址:https://www.cs.cmu.edu/~diyiy/docs/recsys14.pdf
论文介绍: 论文题目是mooc中有限制的问题推荐。顾名思义,就是研究mooc中向用户推荐感兴趣的或者可以解答的问题【话题】,同时可以帮助提出问题的学生更快的解决问题。 与传统的产品推荐不同,论坛中的问题推荐应该同时考虑对学生和问题的约束。这些考虑包括:
- (1)负载平衡——学生不应该承受太多的请求;
- (2)专业技能匹配——不应要求学生解决他们无法解决的问题。 在本文中,我们提出了一个新的约束问题推荐问题来解决上述问题。我们设计了一个情境感知矩阵因子分解模型来预测学生对问题的偏好,然后建立了一个最大成本流模型来管理约束。在三个MOOC数据集上的实验结果表明,我们的方法在优提高论坛整体福利【幸福感】和预测学生可能感兴趣的具体问题方面显著优于基线方法。
论文数据:
还是那3个课程。
研究方法:
问题推荐方法。推荐的约束基于以下几个方面:
- 1、每个学生有一个能力值
- 2、每个问题有一个难度值
- 3、对于每个问题,应该至少有一个学生的能力值大于其难度值
- 4、每个学生容量值得是该学生可以接受的推荐问题数量,应该不少于一个下限L,不多于一个上限R。
- 5、每个问题邀请的学生的数量也会有限制。 我们首先设计了一个情境感知矩阵因子分解模型来预测学生对问题的偏好(关联预测);在接下来的工作中,我们使用预测的关联分数来构建一个最大成本流网络来满足约束条件(约束过滤)。 1、环境感知的相关性预测 使用3个特征表示学生:本周参与问题数、上周发帖数、第几周加入的课程。 使用2个特征表示问题:回复数和问题长度。除此之外,还有一个隐含偏好反馈,通过学生的其他讨论预测学生对问题的偏好。 我们将CQR任务形式化为一个整数线性规划问题,它等价于一个最大成本流模型,然后我们描述了如何求解这个最大成本流模型。所谓线性规划的约束条件,其实就是上面说的5个方面,另外,还有在保证最大最小容量约束的基础上,最小化每个学生的负担,尽量不浪费资源【不用高水平学生解决低难度问题】。
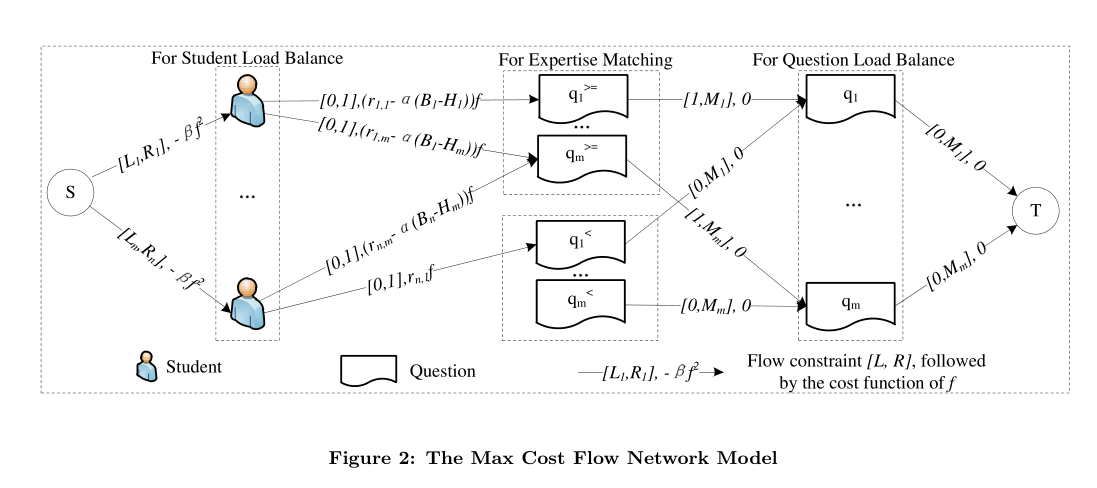
为了使线性优化的目标函数最大化,我们构造了一个凹形成本网络,叫做 maximum concave cost flow(MCCF)。所谓的MCCF即构建了一个有向流动图,从源头流动到目标点,每一个流上面都有代价,作者把目标函数转化为了最大化流代价的问题。
目标函数和图我贴这了,有点难,需要的话再理解为什么这个流动图和目标函数是等价的吧。
最大化\(\begin{aligned} \max & \sum_{u, q} f_{u, q} \cdot r_{u, q}-\beta \cdot \sum_{u}\left(\sum_{q} f_{u, q}\right)^{2}-\alpha \cdot \sum_{q}\left(\sum_{u}\left(\mathbb{I}\left(B_{u} \cdot f_{u, q}>H_{q}\right)\left(B_{u}-H_{q}\right)\right)\right) \end{aligned}\),
使得\(\begin{array}{l}{\forall u \in U, q \in Q, f_{u, q} \in\{0,1\}} ; {L_{u} \leq \sum_{q} f_{u, q} \leq R_{u}, 0 \leq \sum_{u} f_{u, q} \leq M_{q}} ; {\forall q \in Q, \exists v \in U, B_{v} \cdot f_{v, q} \geq H_{q}}\end{array}\)。
实验结果:
使用MAP作为推荐的衡量指标。高于两个Baseline。问题和答案覆盖率略低于贪婪算法,但是整体福利最高。
13、Forum Thread Recommendation for Massive Open Online Courses
论文地址:https://www.cs.cmu.edu/~diyiy/docs/edm14_recom.pdf
论文介绍:
题目是mooc中的论坛线程推荐。这篇论文和上一篇都是做线程推荐的,都是Diyi Yang的论文,方法和工作都是相似的。在这项工作中,我们利用一个基于自适应特征的矩阵分解框架来提出线程建议,从而解决了线程过载问题。我们的方法的一个关键组件是一个特征空间设计,它有效地描述了学生在论坛中的行为,以便匹配线程和用户。此工作包括内容级别建模、社会对等连接和其他论坛活动。我们在一门MOOC课程上的实验结果表明,我们的线程推荐方法有潜力将学生引向他们可能感兴趣的线程。
论文数据:
只在Python课程上面做实验了。
研究方法:
经典矩阵分解(MF)可以有效地解决线程推荐问题。MF构造了一个简化的表示,用于协调用户和线程的一些基于特性的表示。然后可以使用该表示来匹配具有适当线程的用户。然而,与传统的产品推荐不同,MOOC线程推荐的一个重要特性是,学生每次登录论坛,就更有可能参与最近发布的线程。新线程更可能与课程中的当前主题相关,而旧线程可能与它们无关。利用MOOC的特点和现有矩阵分解框架,提出了一种自适应矩阵分解模型。总体框架如下图所示:
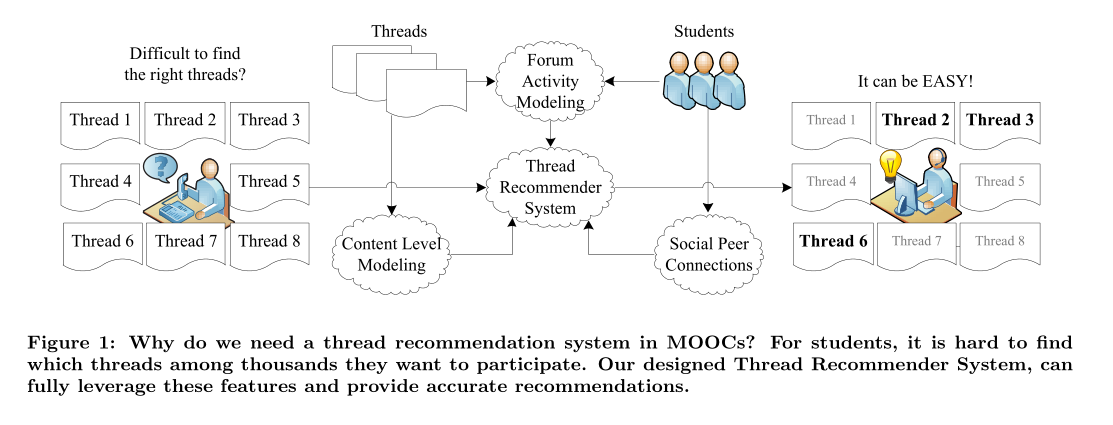
三类特征:全局特性、学生特性和线程特性。何为自适应?有一个时间窗口,只采用当前周之前的窗口大小的周内的数据进行训练,因为早期的论坛与新课程内容无关,用户更可能参与新线程,参与最新课程有关的讨论。并且只推荐活跃线程【时间窗口内至少有一次发帖或者回复】。
上下文建模:线程特有的特征。用线程中的单词包表示线程内容,认为学生对线程感兴趣是因为内容,即基于对这些单词和其中蕴含的主题的兴趣。 社会同学关系:用户特有的特征。经常在论坛上互动的学生对这门课程有着相似的参与条件和学习兴趣。使用与该同学互动最多最亲密的同学捕捉同伴对学生的影响。 线程活动建模:用户和线程的交互特征。学生之前的发帖数、回复数、线程数等等。
实验结果:
推荐效果明显高于所有的Baseline。效果随着窗口大小的增加而略微下降。
14、Constrained Question Recommendation in MOOCs via Submodularity
论文地址:https://www.cs.cmu.edu/~diyiy/docs/cikm14.pdf
论文介绍:
题目是在mooc中通过子模性进行有约束的问题推荐,没错,这一篇和前面两篇一样,也是Diyi Yang同学的论文。与13号论文相比,这一篇与12号论文更像!使用的同样是有约束的线性规划问题,同样的转化为了最大流问题求最优解。不同之处仅仅在于解决问题的方法使用了函数的子模性。
在本文中,我们在论坛中提出了一个带有负载均衡约束的约束问题推荐问题,并使用基于流的模型来生成最优解。特别地,为了解决引入的计算复杂性,我们研究了目标函数的子模性的概念,并提出了一种特定的子模方法来给出近似解。我们在两个大规模开放在线课程(MOOC)论坛数据集上进行了实验,证明了我们的子模块方法在解决受限问题推荐任务方面的有效性和有效性。
论文数据:
还是一样的那3个课程。
研究方法:
研究方法与12号论文完全相同,只是提出了一种方法,利用函数的子模性来解决计算复杂度高难以应用于大规模数据的问题。这种纯数学的东西,就先不看了吧。有缘再见!
实验结果:
这个实验结果偏重于证明他这个子模性计算方法确实可以降低计算复杂度。事实证明确实极大极大地减少了计算时间,降低了计算复杂度。
15、Reputation Systems’ Impact on Help Seeking in MOOC Discussion Forums
论文地址:https://ieeexplore.ieee.org/stamp/stamp.jsp?tp=&arnumber=8118179
论文介绍:
论文题目是声誉系统对MOOC论坛寻求帮助的影响。这篇论文有点长,就看粗略点吧。先来说说什么是声誉系统,顾名思义,就是对一个学生的声誉有影响的东西,比如赞踩数、徽章【帮助别有可能被授予帮助者徽章】、显示的专业技能这些东西。很明显,这些东西对一个学生求助选择对象影响巨大,当然是优先选择那些获得赞数量比较多、有帮助者勋章的人和专业技能比较强的同学求助了,这就是声誉系统对寻求帮助选择的影响了,也是本文的研究内容。这篇论文写的乱七八糟的!
在这篇论文中,我们发现在一个快速的帮助讨论论坛中,对帖子的赞/踩投票会对学生寻求帮助产生负面影响。这种负面影响可以通过使用徽章来消除,徽章是声誉系统的另一个常见特征
论文数据:
论研究方法:
作者用了有个期望价值理论,他说该理论可以被用来更好地理解是什么动机和设计特性影响了学生从特定来源寻求帮助的决定。在策略层面上,帮助期望价值理论指出,一个人是否决定向特定的帮助源寻求帮助,取决于她对帮助源将提供可获得的帮助的期望,以及对帮助源将提供高质量帮助的预期。
作者评估寻求帮助的成本,使用焦虑作为评价指标,一个学生如果寻求帮助而自尊受损,受到打击挖苦,那么寻求帮助的成本就会变大,焦虑也会变大。
实验结果:
16、Investigating how student’s cognitive behavior in MOOC discussion forums affect learning gains
论文地址:http://www.educationaldatamining.org/EDM2015/uploads/papers/paper_89.pdf
论文介绍:
论文数据:
研究方法:
实验结果:
17、Alleviating the Negative Effect of Up and Downvoting on Help Seeking in MOOC Discussion Forums
论文地址:http://www.cs.williams.edu/~iris/website/pubs/2015howley_AlleviatingNegEffOfVotingInMOOCs.pdf
论文介绍:
论文数据:
研究方法:
实验结果:
18、Fostering Discussion across Communication Media in Massive Open Online Courses
论文地址:https://www.isls.org/cscl2015/papers/MC-0404-FullPaper-Rose.pdf
论文介绍:
论文数据:
研究方法:
实验结果:
19、Virtual Teams in Massive Open Online Courses
论文地址:https://www.cs.cmu.edu/~diyiy/docs/aied15_wen.pdf
论文介绍:
论文数据:
研究方法:
实验结果:
20、Peer Influence on Attrition in Massive Open Online Courses
论文地址:https://www.cs.cmu.edu/~diyiy/docs/edm2014_peer.pdf
论文介绍:
论文数据:
研究方法:
实验结果:
21、Positive Impact of Collaborative Chat Participation in an edX MOOC
论文地址:https://www.cs.cmu.edu/~diyiy/docs/aied15.pdf
论文介绍:
论文数据:
研究方法:
实验结果:
22、Supportive technologies for group discussion in MOOCs
论文介绍:
论文数据:
研究方法:
实验结果: